Open-source geo-experiment tools are not interchangeable.
We ran 32,000 simulated experiments across four common marketing scenarios to benchmark four leading open-source geo-experiment tools. Because we use synthetic data where the true campaign effect is known in advance, we can measure how well each tool recovers it.
These four tools are often treated as interchangeable, and they are not. Where they diverge — sharply, at times — is in how they handle uncertainty: how often their confidence intervals contain the true incremental effect, how often they declare winning results that aren't real (false positives), and how often they come back inconclusive when a real incremental effect exists (false negatives).
Every tool forces a tradeoff between those two mistakes, and the choice of tool becomes a choice about which one is more expensive for your business. That's the focus of this report.
CausalPy vs. Google Matched Markets vs. Meta GeoLift vs. Google Causal Impact: A Head-to-Head Simulation Study
We compared four leading open-source geographic-based experimentation tools — CausalPy, Google Matched Markets, Google Causal Impact, and Meta GeoLift — by running each one on thousands of simulated datasets where the true incremental campaign effect is known beforehand. Throughout this report, "effect" means this incremental lift — the sales a campaign genuinely causes, beyond what would have happened anyway.
In this study, every tool sees the same data, the same treatment and control markets, and is scored against the same ground truth. The only thing that differs is the tool being used for the analysis.
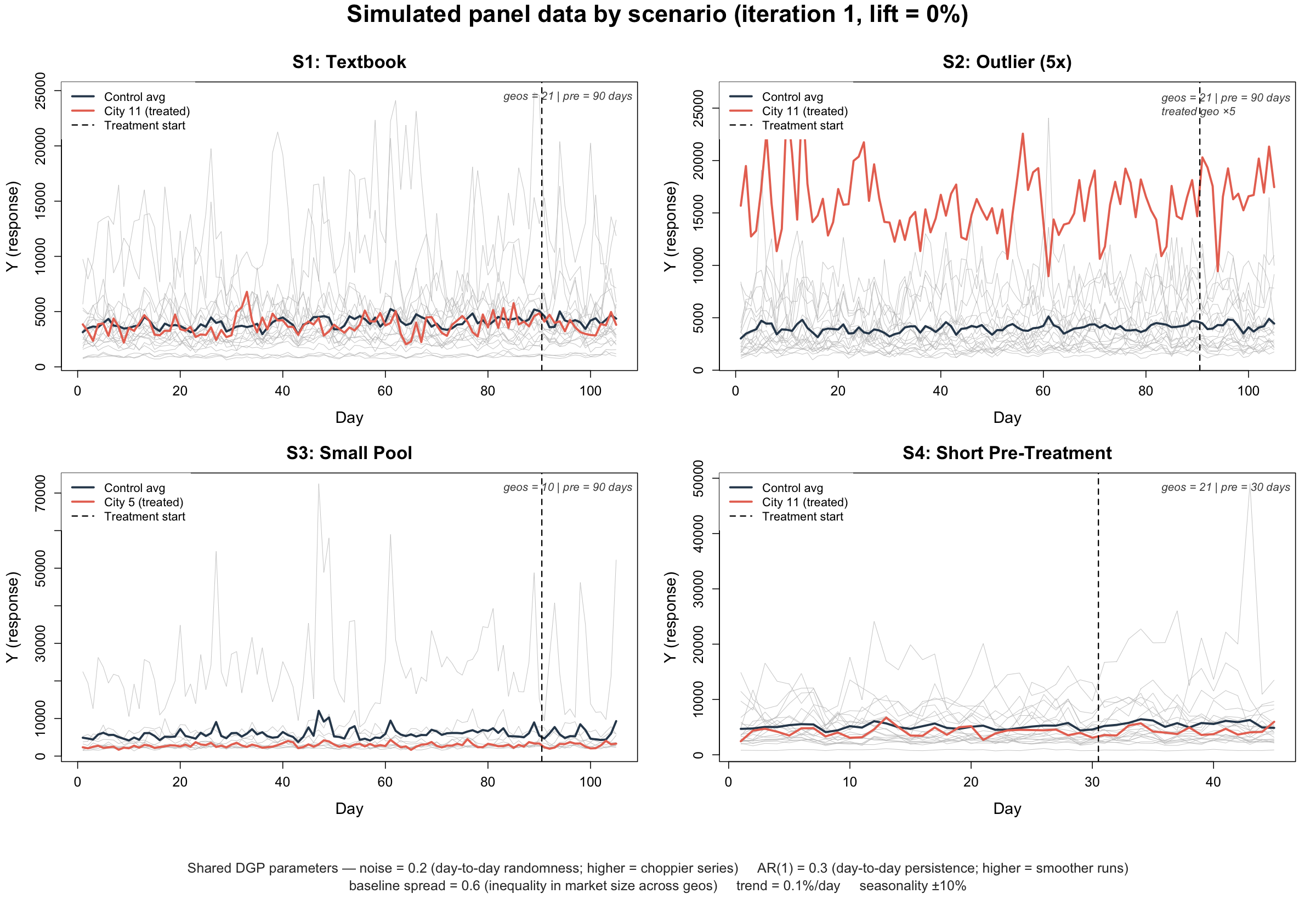
Each simulated dataset is daily sales across many markets, ending with a two-week test period. In that window, one market gets either a 7.5% incremental sales lift (to see whether each tool detects a real effect) or no lift at all (to see how often each tool declares a false win). Each market behaves like a real one: it has its own size, grows slowly over time, has good days and bad days of the week, and experiences random noise where a rough patch tends to bleed into the next day rather than resetting completely.
For the full methodology and technical details, see the Appendix.
Scenarios —Four operating conditions practitioners actually face.
We tested the tools across four scenarios. Each represents a real-world operating condition you'll meet in the course of running an experimentation program.
Baseline
This is clean, well-behaved data with one treated geo and a diverse pool of 20 control markets.
Outlier market
The treated market is 5x larger than the median city in the control pool. In other words, what happens when your CMO insists on testing in New York?
Small control pool
There are only 9 control markets instead of 20, a common issue for companies operating in smaller markets.
Short calibration window
This has 30 days of pre-treatment data instead of 90. Again, a common occurrence where business pressure forces a brand to launch an experiment before they have sufficient pre-experiment data.
Across these scenarios, no tool escaped the tradeoff between false positives and false negatives. The interesting question is which tradeoff each one made.
Key findings —What we learned across 32,000 model fits.
There's no free lunch — every tool forces a tradeoff between two kinds of mistakes.
Every tool in this study forces a choice between two errors: false positives (declaring a winning experiment that isn't real) and false negatives (declaring an experiment inconclusive when a real incremental effect exists). No tool escapes the tradeoff. Which mistake is more expensive for your business is the question that should drive which tool you pick.
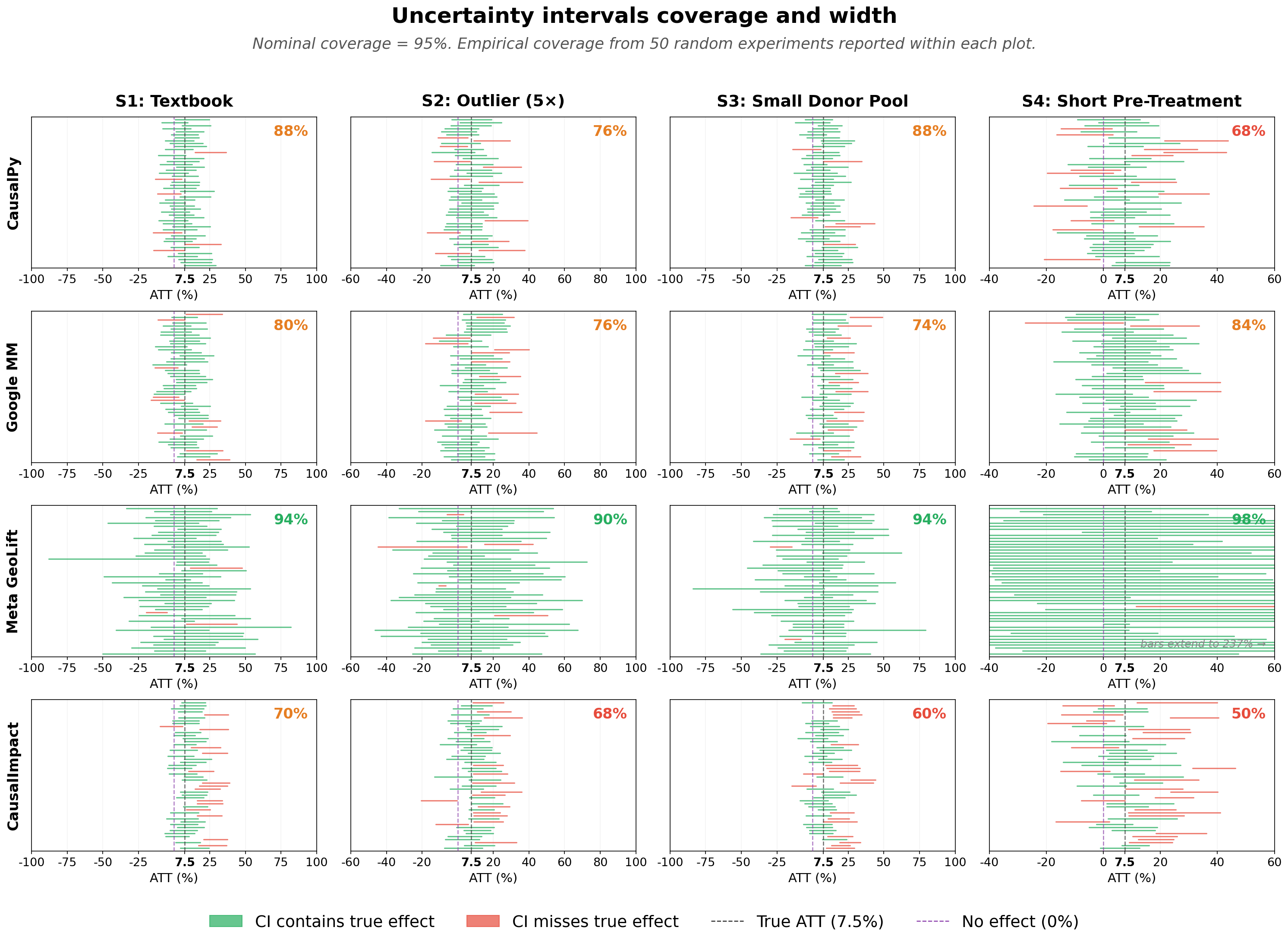
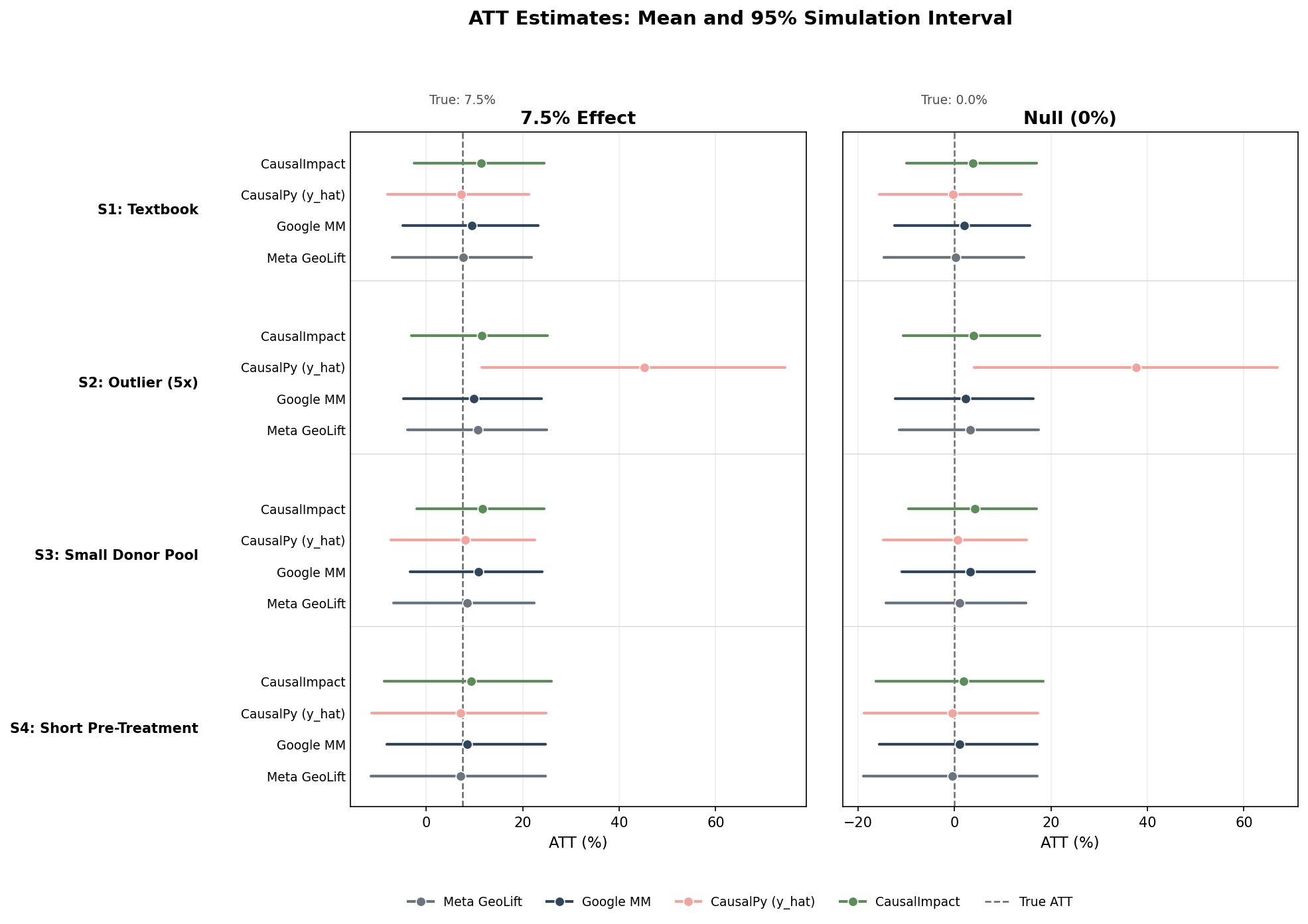
When a tool provides a confidence interval — for example, "the incremental lift is between 5.2% and 10.1% with 95% confidence" — that interval is supposed to contain the true answer 95% of the time. Keeping that promise comes at a cost. A tool can produce wide intervals that reliably contain the true lift. But if those intervals become so wide that they contain zero, the experiment can't declare a statistically significant effect, even when a real one exists.
On the other hand, a tool can produce tighter, more decisive intervals. But those intervals will miss the true incremental lift more often and generate more false alarms. No tool in this study escapes this tradeoff.
Meta GeoLift
Meta GeoLift is the strongest performer on three of four metrics under consideration: its coverage is closest to the 95% target (92–95%), it has the lowest false positive rate (3–5%), and its point estimates are closest to the true incremental lift in most scenarios. The tradeoff is in its ability to detect real incremental effects, where Meta GeoLift's confidence intervals are wide enough such that they frequently contain both the true effect and zero at the same time. This conservatism can become a limitation for practitioners making decisions with output from the tool.
Causal Impact
Causal Impact sits at the opposite end. Its intervals are narrow enough to exclude zero most of the time, which is why it declares a statistically significant lift more often than any other tool — flagging the real 7.5% effect in 52–66% of runs. But narrow intervals that confidently exclude zero also confidently exclude zero when they shouldn't. Causal Impact fires false alarms nearly 30% of the time, and its estimates carry a consistent positive bias that shifts the whole interval high — making campaigns look more effective than they are. Causal Impact is a decisive tool, but it is often confidently wrong.
Google MM and CausalPy
Google MM and CausalPy sit in between, with coverage of 76–86% and false positive rates of 14–25%. Their confidence intervals are wide enough to avoid constant false alarms, but not so wide that every experiment ends inconclusively. The cost is that they under-deliver on the 95% coverage promise in both directions with more false positives than Meta GeoLift and less detection power than Causal Impact.
"The numbers above tell you what each tool's tradeoff actually is. With this context, picking among them becomes a business decision rather than just a statistical one."
When data is scarce, these tradeoffs get worse.
The 30-day pre-treatment scenario (S4) delivers a highly practical finding: it reflects a situation many practitioners have faced, where leadership wants to move faster than the data allows.
With only 30 days of pre-treatment data, Meta GeoLift and Google MM hold up better than CausalPy and Causal Impact. Importantly, the pattern from Finding 1 doesn't ease under data scarcity — it sharpens. Conservative tools become even more conservative and yield more inconclusive experiments. Decisive tools produce more false reads that can mislead marketers.
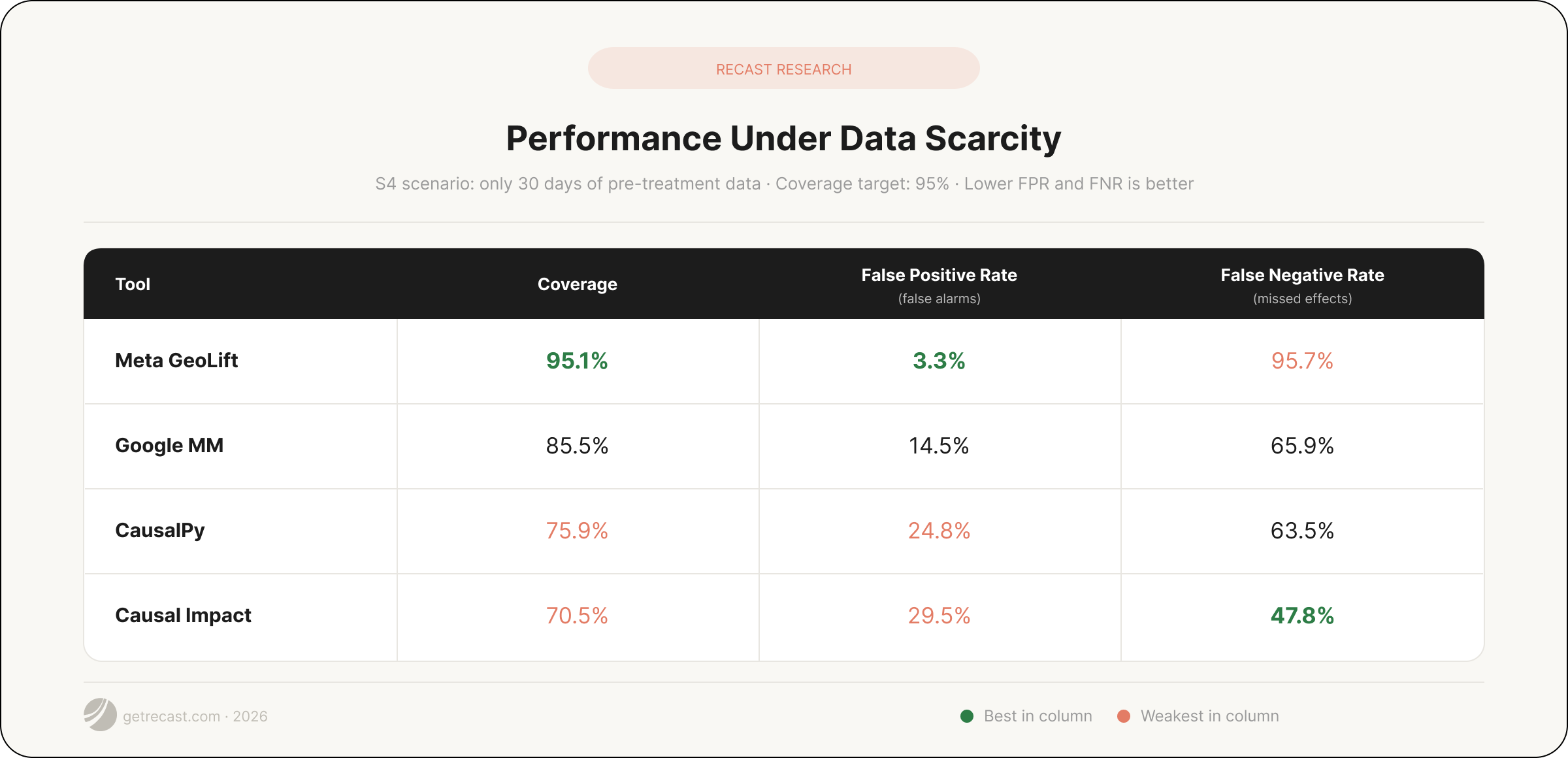
The practical takeaway: 30 days of pre-treatment data is insufficient for reliable inference with any of these tools. But if you're in that situation, Meta GeoLift and Google MM give you a more defensible result.
All four tools get close to the right answer in the easy case.
Across non-outlier scenarios, all four tools largely recover the true 7.5% lift within a few percentage points.
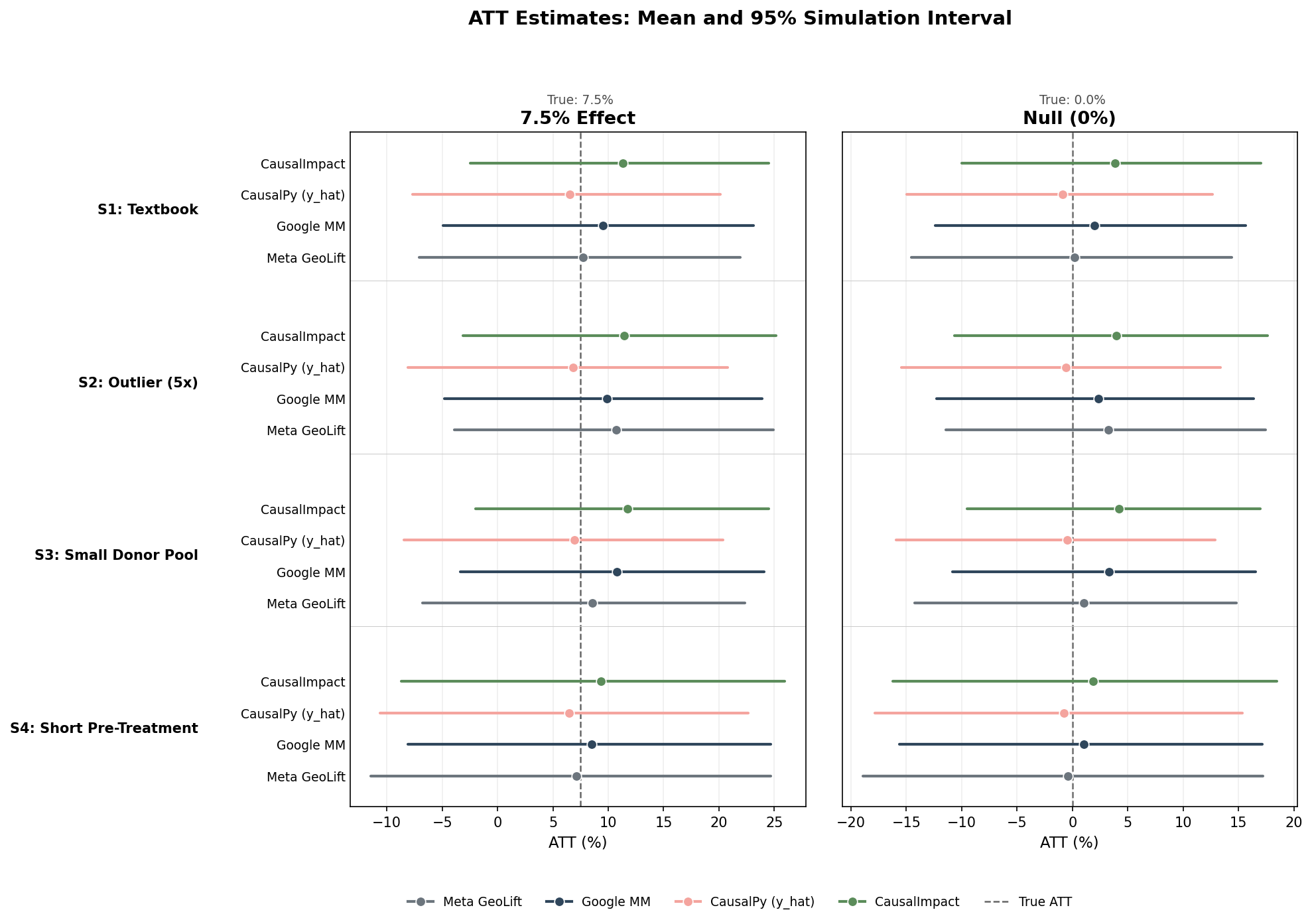
The exception is CausalPy in the outlier scenario (S2), where a data-scaling mismatch produces a near-6× overstatement out of the box (corrected to 6.81% after rescaling — see the Appendix for details). The outlier scenario inflates bias for every tool, but the magnitudes elsewhere stay within a few percentage points of the true lift.
Point estimates alone would tell you these tools are interchangeable. The uncertainty story tells you why they aren't.
Practitioner guidance —What this means if you're choosing a tool.
Meta GeoLift
Meta GeoLift produces the most honest confidence intervals of any tool tested — its stated ranges contain the true effect 92–95% of the time, and it almost never declares a winner that isn't real (false positive rate of 3–5%). The cost is that its intervals are very wide which can make decision-making more difficult. Even though its confidence intervals contain the true 7.5% effect 92–95% of the time, those intervals are wide enough that they also contain zero, and as a result, the test comes back inconclusive in 89% of baseline runs. This makes Meta GeoLift an appropriate choice when scaling budget behind a channel that doesn't actually work — the false positive — is more expensive for your business than missing a real, winning channel.
Google Matched Markets
Google Matched Markets sits in the middle. It gives up some calibration (81–86% coverage) in exchange for more decisive results, with a false positive rate of 14–19% and a tendency to overestimate lift by 1–3 percentage points. When you need experiments to produce actionable answers and can tolerate a higher rate of false alarms, Google MM is a practical default.
CausalPy & Causal Impact
CausalPy requires rescaling the input data before fitting1 — without it, its confidence intervals are far too narrow and its estimates unreliable, particularly when the treated market is much larger than the control markets. With rescaling, it lands in a similar range to Google MM on most metrics. Causal Impact consistently overestimates lift by 2–4 percentage points and has the worst coverage of any tool tested (70–72%). If you are currently using either tool, confirm your results hold up against known ground truth before relying on them for budget decisions — and for CausalPy specifically, ensure your pipeline rescales the data first.
"No tool fully compensates for a poorly designed experiment. When the treated market is dramatically larger than the control markets (the New York problem) confidence intervals across all four tools widen 4–5× and most tools overestimate lift by 2–4 percentage points. At that point, the choice of tool matters less than the choice of test market."
Reproduce it —The full study is open source.
All simulation code, panel generation infrastructure, and analysis scripts are publicly available. The repository includes scripts to generate panels for all four scenarios, wrapper code for each tool, orchestration for parallel execution with checkpointing, and analysis code for every metric, table, and figure in this study.
We built this study to be extended. Change the scenarios, adjust tool configurations, add an estimator, plug in your own data. If you find results that differ from ours, we want to hear about it.
Limitations —What this study doesn't tell you.
Every simulation study is only as good as the assumptions baked into it, and ours are no exception. Our synthetic data was designed to behave like real marketing data, but real geo-experiments add complications we didn't model — markets that move together due to national events, extreme outliers, spillover effects between neighboring cities, and so on.
It's also worth noting that some of GeoLift's strong performance in this study may reflect that our data was built in a way that happens to suit its statistical approach; under messier real-world conditions, the tool rankings could shift. Full details on these limitations are in the Appendix.
This is the first study in a series. Upcoming posts will include deep dives into each individual tool, simulations under more realistic and difficult data conditions, and eventually tests on real campaign data where the true answer isn't known in advance. If the rankings change under harder conditions, we'll report that too.
We recommend running the simulation yourself under different conditions and seeing if the findings hold.